机器学习入门
从房价预测开始
决策树
简单的决策树
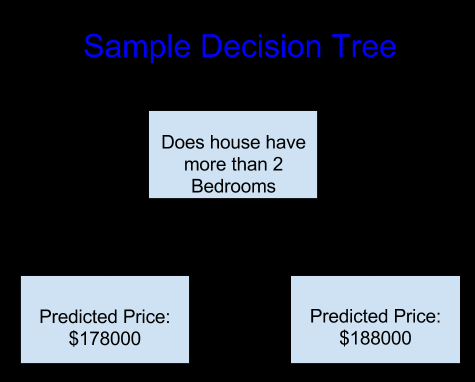
深层决策树
%E5%86%B3%E7%AD%96%E6%A0%91.png)
使用pandas处理数据
X.describe()
X.head()
使用现成的库进行数据训练
1 | from sklearn.tree import DecisionTreeRegressor |
Model Validation
在进行机器学习的时候,不能犯使用数据集进行训练后再用之前进行训练的数据集中的数据进行检验的错误。
为了判别机器学习的效果,需要设定一个指标。
衡量机器学习效果的指标有很多,先从Mean Absolute Error (also called MAE)入手。
学习MAE,先从error入手,error=actual−predicted
平均绝对误差为error绝对值的平均值。
计算MAE的例子
1 | # Data Loading Code Hidden Here |
1 | // 重点: 调用MAE |
由此,错误就发生了。
这里就犯了开头提到的错误,用来预测的数据又用来做了检验。
这个错误叫做”In-Sample” Scores。
Imagine that, in the large real estate market, door color is unrelated to home price.
However, in the sample of data you used to build the model, all homes with green doors were very expensive. The model’s job is to find patterns that predict home prices, so it will see this pattern, and it will always predict high prices for homes with green doors.
scikit-learn的train_test_split函数
scikit-learn自带train_test_split函数从而将数据分成训练集和测试集两部分
示例代码:
1 | from sklearn.model_selection import train_test_split |
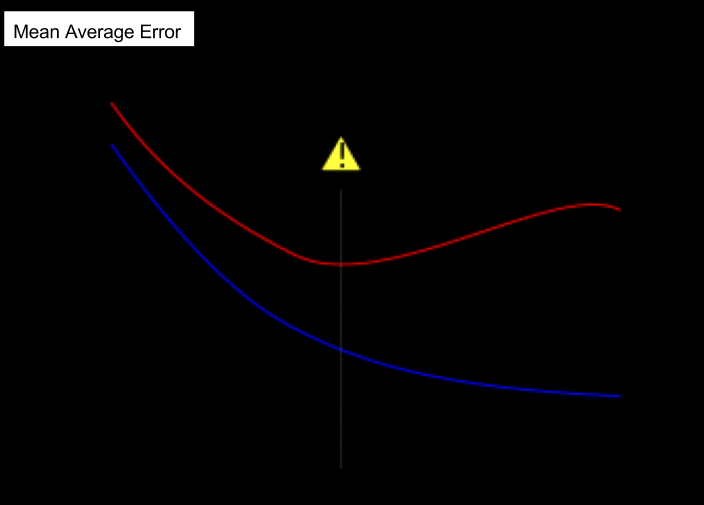
欠拟合和过拟合
示例代码
1 | from sklearn.metrics import mean_absolute_error |
数据集为之前经过分割的数据
使用for循环比较不同深度的预测结果的MAE
一般来说,max_leaf_nodes数值越大,深度越深,决策树的树叶就越多,房子被分的组就越多,就越容易发生过拟合。
1 | # compare MAE with differing values of max_leaf_nodes |
| 叶节点 | 平均绝对误差 |
|---|---|
| Max leaf nodes: 5 | Mean Absolute Error: 347380 |
| Max leaf nodes: 50 | Mean Absolute Error: 258171 |
| Max leaf nodes: 500 | Mean Absolute Error: 243495 |
| Max leaf nodes: 5000 | Mean Absolute Error: 254983 |
Conclusion
Here’s the takeaway: Models can suffer from either:
Overfitting: capturing spurious patterns that won’t recur in the future, leading to less accurate predictions, or
Underfitting: failing to capture relevant patterns, again leading to less accurate predictions.
We use validation data, which isn’t used in model training, to measure a candidate model’s accuracy. This lets us try many candidate models and keep the best one.
实操
1 | candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500] |
1 | //官方解决方法:使用了生成器 |
随机森林
https://www.kaggle.com/dansbecker/random-forests
1 | //使用RandomForestRegressor 换掉DecisionTreeRegressor |
附:代码中random_state的作用
通过设置random_state为一个特定的数值,可以保证下次运行同样的代码时,会出现同样的结果。
如果不设置的话,随着时间的改变,随机种子也会改变,结果也会变得不定。
参考:
Automated machine learning (AutoML)
机器学习过程有七步

在用机器学习模型进行数据顺训练时,要用哪个模型在初学的时候最好的决定方法就是都试一遍积累经验。
使用Google Cloud AutoML Tables可以让其帮我们做决定具体使用哪种模型。

但是可惜这是收费的,虽然可以领取代金券试用,但是需要绑定信用卡。
- Post title:Intro to Machine Learning
- Post author:Willem Zhang
- Create time:2021-04-02 03:06:04
- Post link:https://ataraxia.top/2021/04/01/Intro-to-Machine-Learning/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.